3.4.2 eBPF 和 快速数据路径 XDP
由于 DPDK 完全基于“内核旁路”的思想,它天然无法与 Linux 内核生态很好地结合。
2016 年,Linux Netdev 会议,Linux 内核开发者 David S. Miller[1] 喊出了“DPDK is not Linux”的口号。同年,随着 eBPF 技术成熟,Linux 内核终于迎来了属于自己的“高速公路” —— XDP(eXpress Data Path,快速数据路径)。XDP 因其媲美 DPDK 的性能、背靠 Linux 内核,无需第三方代码库和许可、无需专用 CPU 等多种优势,一经推出便备受关注。
DPDK 技术完全绕过内核,直接将数据包透传至用户空间处理。XDP 正好相反,它在内核空间根据用户的逻辑处理数据包。
在内核执行用户逻辑的关键在于 BPF(Berkeley Packet Filter,伯克利包过滤器)技术 —— 一种允许在内核空间运行经过安全验证的代码的机制。Linux 内核 2.5 版本起,Linux 系统就开始支持 BPF 技术了,但早期的 BPF 主要用于网络数据包的捕获和过滤。到了 Linux 内核 3.18 版本,开发者推出了一套全新的 BPF 架构,也就是我们今天所说的 eBPF(Extended Berkeley Packet Filter)。与早期的 BPF 相比,eBPF 的功能不再局限于网络分析,它几乎能访问所有 Linux 内核关联的资源,逐渐发展成一个多功能的通用执行引擎。
至此,相信读者已经能够察觉到,eBPF 访问 Linux 内核资源的方式与 Netfilter 开放钩子的机制相似。两者的主要区别在于,Netfilter 提供的钩子数量有限,主要面向 Linux 的其他内核模块;而 eBPF 则面向普通开发者,Linux 系统提供了大量钩子供开发者挂载 eBPF 程序。
笔者列举部分钩子供读者参考:
- TC(Traffic Control)钩子:位于内核的网络流量控制层,用于处理流经 Linux 内核的网络数据包。它可以在数据包进入或离开网络栈的各个阶段触发。
- Tracepoints 钩子:Tracepoints 是内核代码中的静态探测钩子,分布在内核的各个子系统中。主要用于内核的性能分析、故障排查、监控等。例如,可以在调度器、文件系统操作、内存管理等处进行监控。
- LSM(Linux Security Modules)钩子:位于 Linux 安全模块框架中,允许在内核执行某些安全相关操作(如文件访问、网络访问等)时触发 eBPF 程序。主要用于实现安全策略和访问控制。例如,可以编写 eBPF 程序来强制执行自定义的安全规则或监控系统的安全事件。
- XDP 钩子:位于网络栈最底层的钩子,直接在网卡驱动程序中触发,用于处理收到的网络数据包,主要用于实现超高速的数据包处理操作,例如 DDoS 防护、负载均衡、数据包过滤等。
从上述钩子可见,XDP 本质上是 Linux 内核在网络路径上设置的钩子,位于网卡驱动层,在数据包进入网络协议栈之前。当 XDP 执行完 eBPF 程序后,通过“返回码”来指示数据包的最终处理决定。
XDP 的 5 种返回码及其含义如下:
- XDP_ABORTED:表示 XDP 程序处理数据包时遇到错误或异常。
- XDP_DROP:在网卡驱动层直接将该数据包丢掉,通常用于过滤无效或不需要的数据包,如实现 DDoS 防护时,丢弃恶意数据包。
- XDP_PASS:数据包继续送往内核的网络协议栈,和传统的处理方式一致。这使得 XDP 可以在有需要的时候,继续使用传统的内核协议栈进行处理。
- XDP_TX:数据包会被重新发送到入站的网络接口(通常是修改后的数据包)。这种操作可以用于实现数据包的快速转发、修改和回环测试(如用于负载均衡场景)。
- XDP_REDIRECT:数据包重定向到其他的网卡或 CPU,结合 AF_XDP[2]可以将数据包直接送往用户空间。
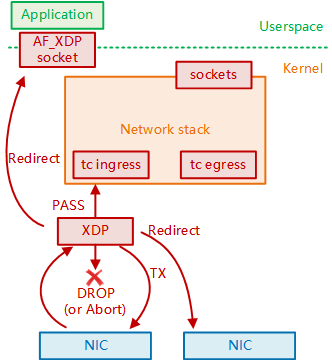
图 3-8 XDP 钩子在 Linux 系统的位置与 5 个动作
eBPF 运行在内核空间,能够极大地减少数据的上下文切换开销,再结合 XDP 钩子,在 Linux 系统收包的早期阶段介入处理,就能实现高性能网络数据包处理和转发。以业内知名的容器网络方案 Cilium 为例,它在 eBPF 和 XDP 钩子(也有其他的钩子)基础上,实现了一套全新的 conntrack 和 NAT 机制。并以此为基础,构建出如 L3/L4 负载均衡、网络策略、观测和安全认证等各类高级功能。
由于 Cilium 实现的底层网络功能独立于 Netfilter,它的连接追踪数据和 NAT 规则不再存储在 Linux 内核默认的 conntrack 表和 NAT 表中。因此,常规的 Linux 命令(如 conntrack、netstat、ss 和 lsof)无法查看这些数据。必须使用 Cilium 提供的查询命令,例如:
$ cilium bpf nat list // 列出 Cilium 中配置的 NAT 规则。
$ cilium bpf ct list global // 列出 Cilium 中的连接追踪条目