7.5 容器持久化存储设计
镜像作为不可变的基础设施,要求在任何环境下能复制出完全一致的容器实例。这意味着,容器内部写入的数据与镜像无关,一旦容器重启,所有写入的数据都会丢失。那容器系统怎么实现数据持久化存储呢?本节,我们由浅入深,先从 Docker 开始,逐步了解容器持久化存储的原理、不同存储类型的特点及其适用场景。
7.5.1 Docker 的存储设计
Docker 通过将宿主机目录挂载到容器内部的方式,实现数据持久化存储。如图 7-21 所示,目前它支持三种挂载方式:bind mount、volume 和 tmpfs mount。
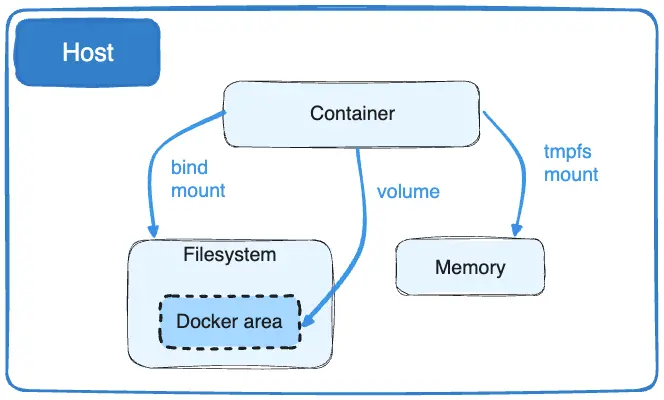
图 7-21 Docker 中持久存储的挂载种类
bind mount 是 Docker 最早支持的挂载类型,也是我们最熟悉的挂载方式。如下命令所示,启动一个 Nginx 容器,并将宿主机的 /usr/share/nginx/html 目录挂载到容器内 /data 目录:
$ docker run -v /usr/share/nginx/html:/data nginx:lastest
上面的挂载,实际上是通过 mount 系统调用实现的。如下代码所示:
// 将宿主机中的 /usr/share/nginx/html 挂载到容器根文件系统的 /data 路径
mount("/usr/share/nginx/html", "rootfs/data", "none", MS_BIND, NULL);
通过 mount 系统调用实现的持久化存储存在以下缺陷:
- 与操作系统的强耦合:容器内的目录通过 mount 挂载到宿主机的绝对路径,这使得容器的运行环境与操作系统紧密绑定。一方面,bind mount 方式无法写入 Dockerfile,否则镜像在其他环境中可能无法启动。另一方面,宿主机中被挂载的目录与 Docker 并无直接关联,其他进程可能会误操作,存在潜在的安全风险;
- 难以满足多样化的存储需求:随着容器广泛应用,存储需求也变得更加复杂。存储位置不仅限于宿主机,还可能涉及外部网络存储;存储介质不仅是磁盘,还可能是内存文件系统(如 tmpfs);存储类型也不局限于文件系统,还包括块设备或对象存储;
- 低效的网络存储处理,对于网络存储,实在没必要先将其挂载到操作系统再挂载到容器内某个目录。Docker 完全可以直接对接 iSCSI、NFS 网络存储协议,绕过操作系统,降低资源占用和访问延迟。
为了解决上述问题,Docker 从 1.7 版本起引入了全新的挂载类型 —— Volume(存储卷):
- 独立的存储空间:Volume 会在宿主机中开辟一个专属于 Docker 的空间(通常在 Linux 中为 /var/lib/docker/volumes/ 目录),这样就避免了 bind mount 对宿主机绝对路径的依赖;
- 支持多种存储系统:考虑到存储类型的多样性,仅依赖 Docker 本身来实现所有存储需求并不现实。因此,Docker 在 1.10 版本中又引入了 Volume Driver 机制,借助社区的力量扩展存储驱动,支持更多存储系统和协议。。
经过一系列的设计,现在 Docker 用户只要通过 docker plugin install 安装额外的第三方卷驱动,就能使用想要的存储方案。
举个具体的例子,请看使用阿里云文件存储(NAS)的示例:
- 先安装阿里云 NAS Volume 插件:
docker plugin install aliyun/aliyun-volume-plugin:latest --alias aliyun-nas --grant-all-permissions
- 接着,使用 docker volume create 命令创建一个挂载到阿里云 NAS 的存储卷,指定 NAS 文件系统的地址:
docker volume create \
--driver aliyun-nas \
--opt nasAddr=<Your_NAS_Address> \
--opt mountDir=/myvolume \
my-aliyun-nas-volume
- 最后,启动容器时,将创建的阿里云 NAS 卷挂载到容器中的目录:
docker run -d -v my-aliyun-nas-volume:/mnt/nas nginx:latest
7.5.2 Kubernetes 的存储设计
我们从 Docker 返回到 Kubernetes 中,同 Docker 类似的是:
- Kubernetes 也抽象出了 Volume 的概念来解决持久化存储;
- 在宿主机中,也开辟了属于 Kubernetes 的空间(该目录是 /var/lib/kubelet/pods/[pod uid]/volumes);
- 也设计了存储驱动(在 Kubernetes 中称 Volume Plugin)扩展支持出众多的存储类型,如本地存储、网络存储(如 NFS、iSCSI)、云厂商的存储服务(如 AWS EBS、GCE PD、阿里云 NAS 等)。
不同的是,作为一个工业级的容器编排系统,Kubernetes 的 Volume 机制比 Docker 更复杂、支持的存储类型更丰富。Kubernetes 支持的存储类型,如图 7-22 所示。

图 7-22 Kubernetes 中的 Volume 分类
乍一看,这么多 Volume 类型实在难以下手。然而,总结起来就 3 类:
- 普通 Volume:主要用于临时数据存储,包括 emptyDir 和 hostPath 等类型;
- emptyDir:在 Pod 删除时数据会被清空;
- hostPath:数据存储在节点本地路径上,如果 Pod 被调度到其他节点,则无法访问原有数据。
- 持久化的 Volume:通过 PersistentVolume(PV)和 PersistentVolumeClaim(PVC)机制实现,支持长期存储且与 Pod 的生命周期解耦。常见的类型包括 NFS、云存储(如 AWS EBS、GCE PD)等;
- 特殊的 Volume:用于管理配置和敏感数据,例如 Secret 和 ConfigMap。严格来说,这类 Volume 并非传统意义上的存储类型,而是通过实现标准的 POSIX(可移植操作系统接口)接口,提供对 Kubernetes 集群中配置信息的便捷访问。这部分内容,笔者就不再展开讨论了。
7.5.3 普通的 Volume
Kubernetes 设计普通 Volume 的初衷并非为了持久化存储数据,而是为了实现容器间的数据共享。请看两个典型示例:
- EmptyDir:这种 Volume 类型常用于 Sidecar 模式。例如,日志收集容器通过 EmptyDir 访问业务容器的日志文件;
- HostPath:与 EmptyDir 不同,HostPath 允许同一节点上的所有容器共享宿主机的本地存储。例如,在 Loki 日志系统中,Pod 挂载宿主机的 HostPath Volume 后,Loki 可以收集并读取宿主机上所有 Pod 生成的日志。
如图 7-23 所示,EmptyDir 类型的 Volume 随 Pod 生命周期而存在。当 Pod 被销毁时,EmptyDir Volume 也会被删除。对于 HostPath,当 Pod 被调度到其他节点时,数据也相当于丢失了。

图 7-23 日志收集器读取业务容器写入的数据
7.5.4 持久化的 Volume
由于 Pod 随时可能被调度到其他节点,如果要实现数据的持久化存储,就得依赖网络存储解决方案。这就是引入 PV(PersistentVolume,持久卷)的原因。
以下是一个 PV 资源的 YAML 配置示例。其 spec 部分定义了关键配置项,包括:存储容量(5Gi)、访问模式(ReadWriteOnce,表示允许单个节点进行读写)、远程存储类型(如 NFS),以及数据回收策略(Recycle,表示在 PV 释放后自动清除数据以供重用)。
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv1
spec:
capacity: #容量
storage: 5Gi
accessModes: #访问模式
- ReadWriteOnce
persistentVolumeReclaimPolicy: Recycle #回收策略
storageClassName: manual
nfs:
path: /
server: 172.17.0.2
直接使用 PV 时,需要详细描述存储的配置信息,这对业务工程师并不友好。业务工程师只想知道我有多大的空间、I/O 是否满足要求,肯定不关心存储底层的配置细节。
为了简化存储的使用,Kubernetes 将存储服务再次抽象,把业务工程师关心的逻辑再抽象一层,于是有了 PVC(Persistent Volume Claim,持久卷声明),这种设计很像软件开发中的“面向对象”思想:
- PVC 可以理解为持久化存储的“接口”,它提供了对某种持久化存储的描述,但不提供具体的实现;
- 而持久化存储的实现部分则由 PV 负责完成。
这样设计的好处是,作为业务开发者,我们只需要与 PVC 这个“接口”进行交互,而不必关心存储的具体的实现是 NFS 还是 Ceph。请看下面 PVC 资源的 YAML 配置示例。可以看到,其中没有任何与存储实现相关的细节。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pv-claim
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
现在,还有个问题,PV 和 PVC 两者之间并没有明确相关的绑定参数,它们之间是如何绑定的?PV 和 PVC 的绑定是自动的,依赖以下两个匹配条件:
- Spec 参数匹配:Kubernetes 会根据 PVC 中声明的规格自动寻找符合条件的 PV。这包括存储容量、所需的访问模式(如 ReadWriteOnce、ReadOnlyMany 或 ReadWriteMany),以及存储类型(如文件系统或块存储);
- 存储类匹配:PV 和 PVC 必须具有相同的 storageClassName,它定义了存储类型和特性,确保 PVC 请求的存储资源与 PV 提供的资源一致。
以下 YAML 配置展示了如何在 Pod 中使用 PVC。当 PVC 成功绑定到 PV 后,NFS 远程存储将被挂载到 Pod 内指定的目录,比如 nginx 容器中的 /data 目录。这样,Pod 内的应用就可以像使用本地存储一样,使用远程存储资源了。
apiVersion: v1
kind: Pod
metadata:
name: test-nfs
spec:
containers:
- image: nginx:alpine
imagePullPolicy: IfNotPresent
name: nginx
volumeMounts:
- mountPath: /data
name: nfs-volume
volumes:
- name: nfs-volume
persistentVolumeClaim:
claimName: pv-claim
7.5.5 PV 的使用:从手动到自动
在 Kubernetes 中,如果没有现成的 PV 满足 PVC 的需求,PVC 会保持在 Pending 状态,直到找到合适的 PV。在此期间,Pod 无法正常启动。对于小规模集群,可以提前手动创建多个 PV 以匹配 PVC,但在大规模集群中,Pod 数量可能达到成千上万,显然无法依靠人工方式提前创建如此多的 PV。
为此,Kubernetes 提供了一套自动创建 PV 的机制 —— 动态供给(Dynamic Provisioning)。相对而言,前面通过人工创建 PV 的方式被称为“静态供给”(Static Provisioning)。
动态供给的关键在于 Kubernetes 的 StorageClass 资源,它充当了 PV 模板的角色,使得 PV 可以根据需要自动生成。声明 StorageClass 时,必须明确两类信息:
- PV 的属性:定义 PV 的特性,包括存储空间的大小、读写模式(如 ReadWriteOnce、ReadOnlyMany 或 ReadWriteMany),以及回收策略(如 Retain、Recycle 或 Delete)等;
- Provisioner 的属性:确定存储供应商(即 Volume Plugin)及其相关参数。Kubernetes 支持两种类型的存储插件:
- In-Tree 插件:这些插件是 Kubernetes 源码的一部分,通常以前缀“kubernetes.io”命名,如 kubernetes.io/aws、kubernetes.io/azure 等。它们直接集成在 Kubernetes 项目中,为特定的存储服务提供支持;
- Out-of-Tree 插件:这些插件根据 Kubernetes 提供的存储接口由第三方存储供应商实现,代码独立于 Kubernetes 核心代码。Out-of-Tree 插件允许更灵活地集成各种存储解决方案,以适应不同的存储需求。
以下是一个 Kubernetes StorageClass 配置示例。该 StorageClass 使用 AWS Elastic Block Store(aws-ebs)作为存储供应商,并通过 type 属性设置为 gp2,表示使用 AWS 的通用型 SSD 卷。
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: standard
provisioner: kubernetes.io/aws-ebs
parameters:
type: gp2
reclaimPolicy: Retain
allowVolumeExpansion: true
mountOptions:
- debug
volumeBindingMode: Immediate
当 StorageClass 资源提交到 Kubernetes 集群后,Kubernetes 会根据 StorageClass 定义的模板以及 PVC 的请求规格,自动创建一个新的 PV 实例。创建完成后,PV 会自动与 PVC 绑定,PVC 的状态从 Pending 转变为 Bound,表示存储资源已准备好。随后,Pod 就能使用 StorageClass 定义的存储类型了。
7.5.6 Kubernetes 存储系统设计
相信大部分读者对如何使用 Volume 已经没有疑问了。接下来,我们将继续探讨存储系统与 Kubernetes 的集成,以及它们是如何与 Pod 相关联的。
在深入这个高级主题之前,我们需要先掌握一些关于操作存储设备的基础知识。Kubernetes 继承了操作系统接入外置存储的设计,将新增或卸载存储设备分解为以下三个操作:
- 准备(Provision):首先,需要确定哪种设备进行 Provision。这一步类似于给操作系统准备一块新的硬盘,确定接入存储设备的类型、容量等基本参数。其逆向操作为 delete(移除)设备。
- 附加(Attach):接下来,将准备好的存储附加到系统中。Attach 可类比为将存储设备接入操作系统,此时尽管设备还不能使用,但你可以用操作系统的 fdisk -l 命令查看到设备。这一步确定存储设备的名称、驱动方式等面向系统的信息,其逆向操作为 Detach(分离)设备。
- 挂载(Mount):最后,将附加好的存储挂载到系统中。Mount 可类比为将设备挂载到系统的指定位置,这就是操作系统中 mount 命令的作用,其逆向操作为卸载(Unmount)存储设备。
注意
如果 Pod 中使用的是 EmptyDir、HostPath 这类 Volume,并不会经历附加/分离的操作,它们只会被挂载/卸载到某一个 Pod 中。
Kubernetes 中的 Volume 创建和管理主要由 VolumeManager(卷管理器)、AttachDetachController(挂载控制器)和 PVController(PV 生命周期管理器)负责。前面提到的 Provision、Delete、Attach、Detach、Mount 和 Unmount 操作由具体的 VolumePlugin(第三方存储插件,也称 CSI 插件)实现。
图 7-24 展示了一个带有 PVC 的 Pod 创建过程:
- 首先,用户创建一个包含 PVC 的 Pod,该 PVC 要求使用动态存储卷;
- 默认调度器 kube-scheduler 根据 Pod 配置、节点状态、PV 配置等信息,将 Pod 调度到一个合适的节点中;
- PVController 会持续监测 ApiServer,当发现一个 PVC 已创建但仍处于未绑定状态时,它会尝试将一个 PV 与该 PVC 进行绑定。首先,PVController 会在集群内查找适合的 PV;如果找不到相应的 PV,它会调用 Volume Plugin 中的接口执行 Provision 操作。Provision 过程包括从远程存储介质创建一个 Volume,并在集群中创建一个 PV 对象,然后将此 PV 与 PVC 绑定;
- 如果一个 Pod 被调度到某个节点后,它所定义的 PV 还没有被挂载,AttachDetachController 就会调用 Volume Plugin 中的接口,把远端的 Volume 挂载到目标节点中的设备上(例如:/dev/vdb);
- 在节点中,当 VolumeManager 发现一个 Pod 已调度到自己的节点上并且 Volume 已经完成挂载时,它会执行 mount 操作,将本地设备(即刚才得到的 /dev/vdb)挂载到 Pod 在节点上的一个子目录
/var/lib/kubelet/pods/[pod uid]/volumes/kubernetes.io~iscsi/[PV name](以 iSCSI 类型的存储为例); - 最后,Kubelet 启动 Pod,并使用 bind mount 方式将已挂载到本地目录的卷映射到 Pod 容器内。

图 7-24 Pod 挂载持久化 Volume 的过程
上述流程中第三方存储供应商实现 Volume Plugin 即 CSI(Container Storage Interface,容器存储接口)插件。CSI 是一个开放性的标准,目标是为容器编排系统(不仅仅是 Kubernetes,还包括 Docker Swarm 和 Mesos 等)提供统一的存储接口。
CSI 插件在实现上是一个可执行的二进制文件,它以 gRPC 的方式对外提供了三个主要的 gRPC 服务:Identity Service、Controller Service、Node Service 用于卷的管理、挂载和卸载等操作。笔者介绍如下:
其中,Identity Service 用于对外暴露插件本身的信息,它的接口定义如下:
service Identity {
// 返回插件的名称、版本和其他元数据。
rpc GetPluginInfo(GetPluginInfoRequest)
returns (GetPluginInfoResponse) {}
// 返回插件支持的功能,例如是否支持卷的快照等。
rpc GetPluginCapabilities(GetPluginCapabilitiesRequest)
returns (GetPluginCapabilitiesResponse) {}
rpc Probe (ProbeRequest)
returns (ProbeResponse) {}
}
Controller Service 管理卷的生命周期,包括创建、删除和获取卷的信息,它的接口定义如下所示。可以看出,接口中定义的操作就是图 7-24 Master 节点中 准备(Provision)和 附加(Attach)的逻辑。
service Controller {
// 创建一个新卷,并返回该卷的详细信息。
rpc CreateVolume (CreateVolumeRequest)
returns (CreateVolumeResponse) {}
// 删除指定的卷。
rpc DeleteVolume (DeleteVolumeRequest)
returns (DeleteVolumeResponse) {}
// 将卷绑定到特定的节点,准备后续的挂载操作。
rpc ControllerPublishVolume (ControllerPublishVolumeRequest)
returns (ControllerPublishVolumeResponse) {}
// 从节点解绑卷,准备进行删除或其他操作。
rpc ControllerUnpublishVolume (ControllerUnpublishVolumeRequest)
returns (ControllerUnpublishVolumeResponse) {}
...
Node Service 主要由 Kubelet 调用处理卷在节点上的挂载和卸载操作。它的接口定义如下:
service Node {
// 将卷挂载到节点的设备上,使其准备好被 Pod 使用。
rpc NodeStageVolume (NodeStageVolumeRequest)
returns (NodeStageVolumeResponse) {}
// 将卷从节点的设备中卸载。
rpc NodeUnstageVolume (NodeUnstageVolumeRequest)
returns (NodeUnstageVolumeResponse) {}
// 在指定的 Pod 中将卷挂载到容器的文件系统上。
rpc NodePublishVolume (NodePublishVolumeRequest)
returns (NodePublishVolumeResponse) {}
...
CSI 插件机制为存储供应商和容器编排系统之间的交互提供了标准化的接口。云存储厂商只需根据这一标准接口实现自己的云存储插件,即可无缝衔接 Kubernetes 的底层编排系统,Kubernetes 也由此具备了多样化的云存储、备份和快照等能力。
7.5.7 存储分类:块存储、文件存储和对象存储
得益 Kubernetes 的开放性设计,通过图 7-25 感受提供了 CSI 插件支持的存储生态,基本上包含了市面上所有的存储供应商。

图 7-25 CNCF 下的 Kubernetes 存储生态
上述众多的存储系统无法一一展开,但作为业务开发工程师而言,直面的问题是,我应该选择哪种存储类型?无论是内置的存储插件还是第三方的 CSI 存储插件,总结提供的存储服务类型就 3 种:块存储(Block Storage)、文件存储(File Storage)和对象存储(Object Storage)。这三种存储类型特点与区别,笔者介绍如下:
块存储:块存储是最接近物理介质的一种存储方式,常见的硬盘就属于块设备。块存储不关心数据的组织方式和结构,只是简单地将所有数据按固定大小分块,每块赋予一个用于寻址的编号。数据的读写通过与块设备匹配的协议(如 SCSI、SATA、SAS、FCP、FCoE、iSCSI 等)进行。
块存储处于整个存储软件栈的底层,不经过操作系统,因此具有超低时延和超高吞吐。但缺点是每个块是独立的,缺乏集中控制机制来解决数据冲突和同步问题。因此,块存储设备通常不能共享,无法被多个客户端(节点)同时挂载。在 Kubernetes 中,块存储类型的 Volume 的访问模式必须是 RWO(ReadWriteOnce),即可读可写,但只能被单个节点挂载。
由于块存储不关心数据的组织方式或内容,接口简单朴素,因此主要用于文件系统、专业备份管理软件、分区软件以及数据库,而非直接提供给普通用户。
文件存储:块设备存储的是最原始的二进制数据(0 和 1),对于人类用户来说,这样的数据既难以使用也难以管理。因此,我们使用“文件”这一概念来组织这些数据。所有用于同一用途的数据按照不同应用程序要求的结构方式组成不同类型的文件,并用不同的后缀来指代这些类型。每个文件有一个便于理解和记忆的名称。当文件数量较多时,通过某种划分方式对这些文件分组,所有文件和目录形成一个树状结构。再补充权限、文件名称、创建时间、所有者、修改者等元数据信息。
这种定义文件分配、实现方式、存储信息和提供功能的标准被称为“文件系统”(File System)。常见的文件系统有 FAT32、NTFS、exFAT、ext2/3/4、XFS、BTRFS 等等。如果文件存储在网络服务器中,客户端用类似访问本地文件系统的方式访问远程服务器上的文件,这样的系统称为“网络文件系统”。常见的网络文件系统有 Windows 网络的 CIFS(Common Internet File System,也称 SMB)和类 Unix 系统的 NFS(Network File System)。
对象存储:文件存储的树状结构和路径访问方式便于人类理解、记忆和访问,但计算机需要逐级分解路径并查找,最终定位到所需文件,这对于应用程序而言既不必要,也浪费性能。块存储则性能出色,但难以理解且无法共享。选择困难症出现的同时,人们思考:“是否可以有一种既具备高性能、实现共享、又能满足大规模扩展需求的新型存储系统?”。于是,对象存储应运而生。
对象存储中的“对象”可以理解为元数据与逻辑数据块的组合:
- 元数据提供了对象的上下文信息,如数据类型、大小、权限、创建人、创建时间等;
- 数据块则存储了对象的具体内容。
对象存储中,所有数据处于同一层次,通过唯一标识来识别和查找(扩展简单),非常适合处理数据量大、增速快的非结构化数据(如视频、图像等)。
最著名的对象存储服务是 AWS S3(Simple Storage Service),它的接口规范已经成为业内对象存储服务事实标准。如果你考虑降低云成本,也可以通过开源项目如 Ceph、Minio 或 Swift 等自建对象存储服务。