6.2 日志与复制状态机
如果统计分布式系统有多少块基石,“日志”一定是其中之一。
这里“日志”并不是常见的通过 log4j 或 syslog 输出的文本。而是 MySQL 中的 binlog(Binary Log)、MongoDB 中的 Oplog(Operations Log)、Redis 中的 AOF(Append Only File)、PostgreSQL 中的 WAL(Write-Ahead Log)...。它们虽然名称不同,但共同特点是只能追加、完全有序的记录序列。
图 6-1 展示了日志的结构,可以看出,日志是有序且持久化的记录序列。新记录会从末尾追加,而读取时则按“从左到右”的顺序进行扫描。
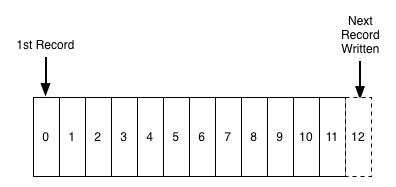
图 6-1 日志是有序的、持久化的记录序列 图片来源
有序的日志记录了“何时发生了什么”,这一点可以通过以下两种数据复制模型来理解。
- 主备模型(Primary-backup):又称“状态转移”模型,主节点(Master)负责执行如“+1”、“-2”的操作,将操作结果(如“1”、“3”、“6”)记录到日志中,备节点(Slave)根据日志直接同步结果。
- 复制状态机模型(State-Machine Replication):又称“操作转移”模型,日志记录的不是最终结果,而是具体的操作指令,如“+1”、“-2”。指令按照顺序被依次复制到各个节点(Peer)。如果每个节点按顺序执行这些指令,各个节点最终将达到一致的状态。
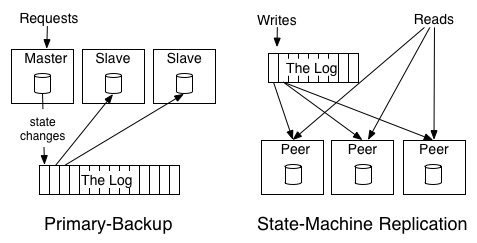
图 6-2 分布式系统的两种数据复制模型
无论哪一种模型,它们都揭示了:“顺序是节点之间保持一致性的关键因素”。如果打乱了操作的顺序,就会得到不同的运算结果。
接下来,进一步解释基于“复制状态机”(State Machine Replication)工作模型构建的分布式系统,其基本原理如图 6-3 所示。
复制状态机的基本原理
两个“相同的” (identical)、“确定的” (deterministic) 进程:
- 相同的:进程的代码、逻辑、以及配置完全一致,它们在设计和实现上完全相同;
- 确定的:进程的行为是完全可预测的,不能有任何非确定性的逻辑,比如随机数生成或不受控制的时间依赖。
如果它们以相同的状态启动,按相同的顺序获取相同的输入。那么,它们一定会达到相同的状态。
共识算法(图中的 Consensus Module,Paxos 或者 Raft 算法)通过消息,将日志广播至所有节点,它们就日志什么位置,记录什么(序号为 9,执行 set x=3)达成共识。换句话说,所有的节点中,都有着相同顺序的日志序列,
// 日志
{ "index": 9, "command": "set x=3" }
节点内的进程(图中的 State Machine)按顺序执行日志序列,操作具有全局顺序。因此,所有节点最终将达到一致的状态。多个这样的进程结合有序日志,就构成了 Apache Kafka、Zookeeper、etcd、CockroachDB 等分布式系统中的关键组件。

图 6-3 复制状态机工作模型 图片来源